구글 클라우드 플랫폼 자격증 세개 다 따자마자 이직하게 되면서 아마존 웹 서비스만 사용하는 중인데요. 검색을 해보면 한글자료는 충분한것 같지 않아서 이래저래 겪은 내용을 짧게 정리해보려고 합니다. 메인 화면을 보면 제가 자주 사용했던 서비스부터 뜨는데요. EC2, S3, SageMaker를 주로 사용합니다.
가입하고 기본적인 세팅하는건 다른 블로그에도 정말 잘 나와있어서요. 이 부분은 건너뛸게요. 실무자가 사용하면서 느낀점이나 디버깅이나 유용한점이 있으면 그런내용을 위주로 올려보려고 합니다. 처음엔 그냥 주저리 적어보자면..
EC2 : Elastic Computer Cloud
EC2를 통해 가상 컴퓨터를 만든다라고 생각하면 가장 간단할것 같습니다. 데이터를 저장하고, 알고리즘을 짜고 하는 것들을 제 컴퓨터가 아니라, 가상환경에서 할 수 있는데요. 제 컴퓨터가 아니라, 가상환경의 새로운 컴퓨터를 만들 수 있는데 컴퓨터 사양도 제 맘대로 선택할 수 있죠. 메모리는 어느정도로 해야할지, GPU나, CPU는 어느정도로 해야할지.. 선택해서 컴퓨터를 만들어서 그 컴퓨터에 접속하는 것입니다. 물론 사양이 좋을수록 비싸겠죠. 그래서 인스턴스를 생성하고 나서 일을 다 한뒤 중단시키지 않으면 돈이 계속 나가게 됩니다.
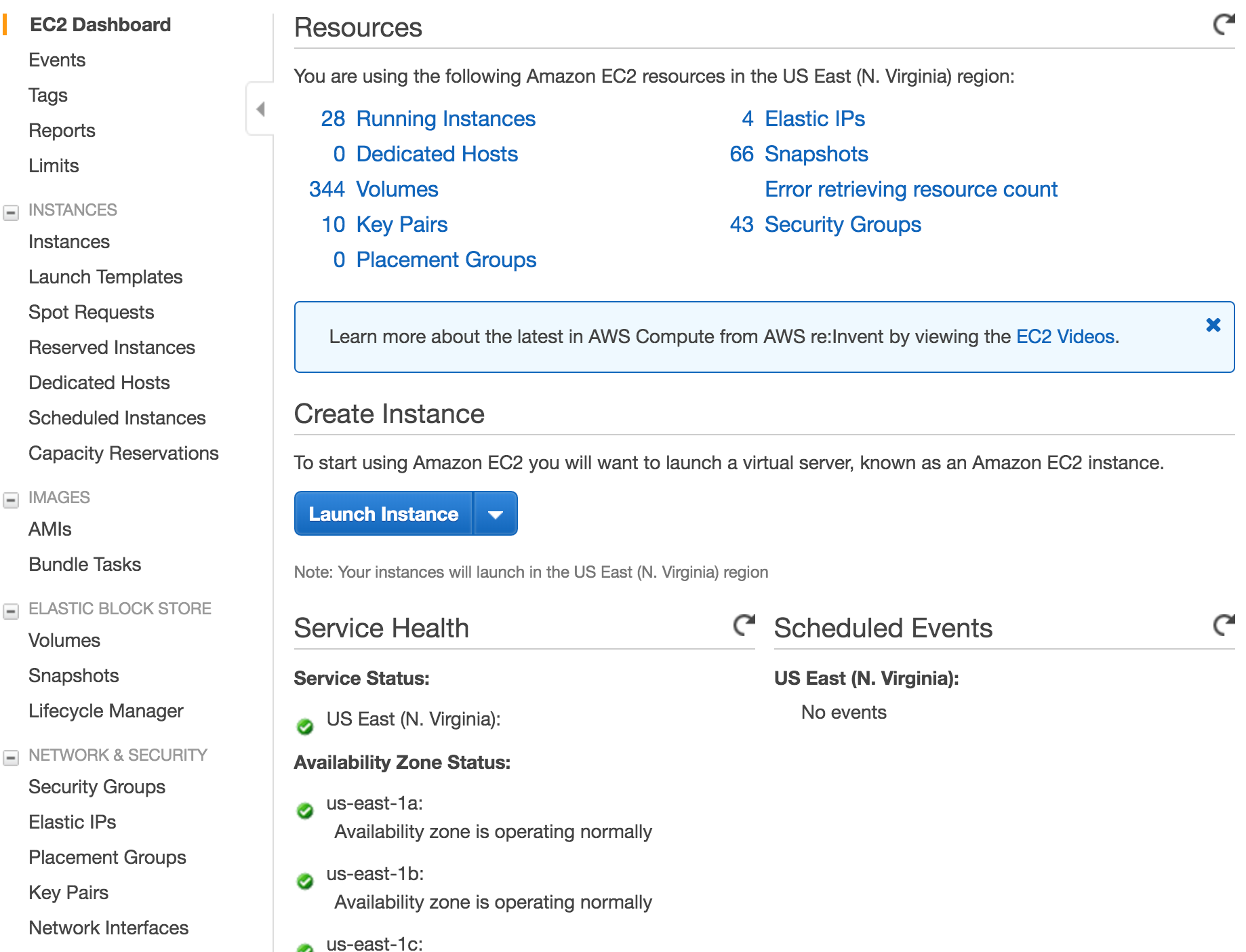
그림을 보면 28개의 인스턴스(Instances)가 돌아가고 있다고 뜨는데요. 28개의 컴퓨터가 지금 일하고 있단 뜻입니다. 데이터가 정말 클때, 아니면 계산이 복잡할때 parallel로 쓰기도 하는데요. 그러니까 컴퓨터를 여러대 설정해서 동시에 계산하도록 하는거죠. 그래서 팀원보다 인스턴스, 즉 가상으로 돌아가는 컴퓨터의 갯수가 훨씬 더 많습니다. 제 컴퓨터를 들어가면 뭐가 보이냐면... 주피터 노트북이 보입니다. 그걸로 파이썬으로 데이터 분석하고 모델짜고 그래요.
S3 Bucket:
버켓, 바스켓, 그러니까 박스라고 하면 뭘 담을 수 있겠죠. 데이터는 이미지든 저장소를 의미합니다. Bucket을 만들어서 그 안에 폴더를 여러개 생성할 수 있어요. 사진을 캡쳐하기엔 다 블러 처리해야되어서 캡쳐는 건너뛰겠습니다. S3에서는 누가 접속 할 수 있는지 아닌지 그런게 중요하고요. 왜냐하면 클라이언트 데이터를 일반사람들이 볼 수 있으면 안되니까요. boto3나 SageMaker를 사용할때 이 S3에 접속하게 됩니다.
SageMaker
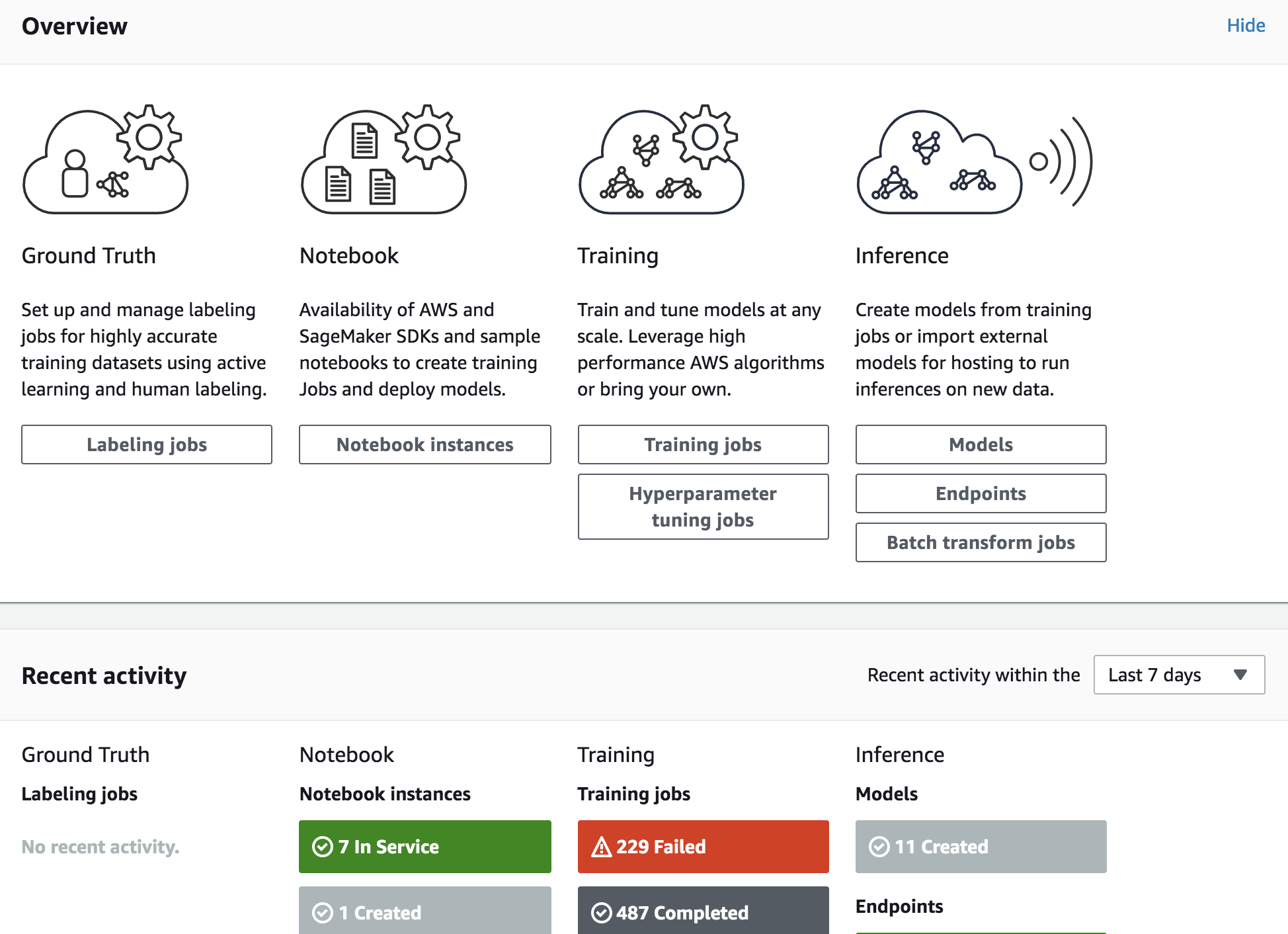
세이지메이커는 이제까지 XGBoost모델과 Linear Learner이렇게 두개 사용해보았는데요. 세이지메이커는 머신러닝의 수작업을 최소화한다며 내놓은 그러니까 아마존이 제공하는 알고리즘을 사용할 수 있도록 하는 툴인데요. 저...Training Failed된거 보이시나요. 또르르....몇번밖에 안썼다보니 아직 손에 착착 붙진 않습니다만 모델 결과를 따져봤을때 굉장히 우수했어요. hyper parameter tuning도 굉장히 쉽고요. 다만 아쉬운점이 있다면 EC2처럼 여러사람이 볼륨을 쉐어할 수 없다는거.. 진짜 없는건지 아니면 제가 잘 모르는건지 모르겠지만요. (쉽게 푸는 설명은 다음에 할게요) 처음엔 에러때문에 디버깅하느라 너무 짜증났는데 익숙해지면서 참 편하게 잘 만들었구나...란 생각이 들었습니다.